File Load utility: FLOD and FILELOAD commands: Difference between revisions
m Clone text about FILEORG x'100' from the FILEORG_parameter page |
m minor formatting |
||
| Line 1: | Line 1: | ||
<div class="toclimit-3"> | <div class="toclimit-3"> | ||
<p> | <p> | ||
A <var>FLOD</var> or a <var>FILELOAD</var> command is followed by a series of file load statements that comprise the file load program. The program is terminated by an <var>END</var> statement, beginning in column 1.</p> | |||
<ul> | <ul> | ||
<li>If you are doing a multistep File Load procedure, the <var>FLOD</var> command | <li>If you are doing a multistep File Load procedure, the <var>FLOD</var> command | ||
| Line 7: | Line 7: | ||
<li>If you are doing a one-step procedure, use the <var>FILELOAD</var> command.</li> | <li>If you are doing a one-step procedure, use the <var>FILELOAD</var> command.</li> | ||
</ul> | </ul> | ||
<p> | <p> | ||
These commands place the file in deferred update mode, in which updates to Tables C and D are deferred to deferred update data sets and are applied later to Tables C and D.</p> | |||
<p class="note"><b>Note:</b> | |||
<var>FILEORG</var> X'100' files cannot be loaded via <var>[[FLOD_command|FLOD]]</var> or | <var>FILEORG</var> X'100' files cannot be loaded via <var>[[FLOD_command|FLOD]]</var> or | ||
<var>[[FILELOAD_command|FILELOAD]]</var> except with a <var class="product"> | <var>[[FILELOAD_command|FILELOAD]]</var> except with a <var class="product"> | ||
[[Media:FrelrNew.pdf|Fast/Reload]]</var> <var>Load All Information</var> (<var>LAI</var>) | [[Media:FrelrNew.pdf|Fast/Reload]]</var> <var>Load All Information</var> (<var>LAI</var>) | ||
<var>FLOD/FILELOAD</var> program.</p> | <var>FLOD/FILELOAD</var> program.</p> | ||
===Including the FLOD or FILELOAD command in your run=== | ===Including the FLOD or FILELOAD command in your run=== | ||
Revision as of 20:12, 4 August 2015
A FLOD or a FILELOAD command is followed by a series of file load statements that comprise the file load program. The program is terminated by an END statement, beginning in column 1.
- If you are doing a multistep File Load procedure, the FLOD command marks the beginning of a file load program.
- If you are doing a one-step procedure, use the FILELOAD command.
These commands place the file in deferred update mode, in which updates to Tables C and D are deferred to deferred update data sets and are applied later to Tables C and D.
Note: FILEORG X'100' files cannot be loaded via FLOD or FILELOAD except with a Fast/Reload Load All Information (LAI) FLOD/FILELOAD program.
Including the FLOD or FILELOAD command in your run
Include the FLOD or FILELOAD command and its associated file load program in the CCAIN data set, along with any other Model 204 commands needed to prepare the file for loading or to manipulate or check the data after loading.
Note: There can be only one FLOD, FILELOAD, or Z command specified in any given File Load job step.
Getting information about a FLOD or FILELOAD run
Some of the characteristics of the File Load run such as the number of records deleted or the number of fields added during the run are kept as counters that are printed at the end of the run. These counters are listed in FLOD and FILELOAD command output. A histogram listing the distribution of deferred update record lengths along with the number of records for each range of lengths is also displayed for variable-length deferred update data sets. It can be used as an aid to setting the variable-length sort parameter, and is illustrated in Setting the variable-length parameter(vl).
Double-checking your file load run
If you know how many records you are loading, you can use the SOUL FPC (Find and Print Count) construct to ensure that all records have been loaded.
Loading nondeferrable fields
If you are loading fields whose updates should not be deferred, it is not sufficient to specify the NON-DEFERRABLE attribute in order to override the deferral of updates for these fields. (In single-user File Load runs, the NON-DEFERRABLE attribute is ignored by Model 204.) See Overriding deferred updates for a description of the techniques available to override deferred updates.
Do not use RRN files in deferred update mode
Rocket Software suggests that you do not use deferred update mode with Reuse Record Number files except where you are performing simple record adds (such as reorganizing files). Doing so could cause you to lose updates without warning. See RRN files and deferred update mode for more information.
FLOD command
The FLOD command marks the beginning of a file load program. This command is followed by the file load statements described starting on File Load statements: overview. The procedure ends with the word END, beginning in column 1.
Syntax
The format of the FLOD command is:
FLOD k,n,m . . . END
Where:
- k specifies the maximum number of records to be loaded into the Model 204 file:
- If k is -1, FLOD loads all records into the Model 204 file.
- If k is any negative number except -1, the number is converted into a 32-bit unsigned number, N, and N records are processed.
- n specifies the maximum number of times the statements in the file load program are to be executed:
- If n is 0, the FLOD or FILELOAD code is compiled, but is not executed.
- If n is -1, FLOD keeps making passes through the code until the process is stopped by another condition (such as EOF)
- m specifies the number of input records to skip before starting the File Load process, which is helpful for breaking up the load process so that dumps (backups) can be taken during large loads:
- If m is -1, all records are skipped.
- If m is any negative number except -1, the number is converted into a 32-bit unsigned number,
N, and FLOD skipsNrecords before processing begins.
Usage
Each time the END statement is encountered during execution, Model 204 begins again with the first statement following the FLOD command. The procedure continues to execute until one of the following occurs:
- All the records in the input data set have been processed.
- k records have been added to the Model 204 file.
- n passes have been made through the file load program.
Thus, either k or n can be used to limit File Load processing and to load only a sample of the data.
To process all the input records, set both k and n to -1.
Example
The following command specifies that all input records be processed starting with the first record (that is, skip 0 records):
FLOD -1,-1, 0
FILELOAD command
To perform a one-step file load, use the FILELOAD command to mark the beginning of a file load program. This command is followed by the file load statements described starting on File Load statements: overview. The procedure ends with the word END, beginning in column 1.
FILELOAD command processing
The FILELOAD command attaches one or two sort subtasks to do the sorting required to load index and FRV entries efficiently. These subtasks run asynchronously with Model 204 (except under z/VM, which does not support true subtasking). Two buffers are used for the sorts. Model 204 fills the second buffer while the sort is emptying the first. After the records are sorted, the same double-buffering mechanism is used to pass the records back to Model 204.
Syntax
The complete format of the FILELOAD command is:
FILELOAD k,n,m [,[s1] [,[s2] [,[s3] [,[s4] [,vl]]]]] . . . END
Where:
- k, n, and m have the meanings described for the FLOD command in FLOD command, above.
- s1 represents the amount of memory that the sort package uses for sorting the deferred update index records produced by the file load program. If s1 is omitted or is not a positive integer, a default value of 50,000 bytes (64K for z/VM) is used for the sort work space.
Note: Make the s1 parameter as large as possible, especially for sorts involving many records. It is important to increase s1 for large sorts.
- s2 represents the amount of memory used for sorting the deferred update FRV index records. If s2 is omitted or is not a positive integer, a default value of 50,000 bytes (64K for z/VM) is used. For 3380 disk drives the minimum values for s1 and s2 are 64,000 bytes.
- s3 represents the amount of memory allocated for the two buffers used to pass data from Model 204 to the sorts. This parameter specifies the combined size of the two buffers. The core specified in s3 is evenly divided between the two buffers, and the default value of s3 is 8000 bytes. The minimum value accepted is 48 bytes, but such a small size is not recommended. A larger value of s3 can produce a noticeable performance improvement. However, increasing s1 normally has a greater effect on performance than a corresponding increase in s3.
- s4 represents the amount of memory allocated for the two buffers used to pass data from the sorts to Model 204. s4 is ordinarily equal in size to s3 and is set equal to s3 by default.
- vl specifies the maximum sort record length in variable-length record sorts. (vl corresponds to the L2 of the RECORD sort statement.)
The vl parameter is required when ORDERED fields are updated by the file load program. For efficiency, do not use the vl parameter if ORDERED fields are not updated. For more information about the vl parameter and how to select a value for it, see Setting the variable-length parameter(vl).
Examples
To specify a value for s2, but not s1, supply two consecutive commas before s2, as follows:
FILELOAD k,n,m,,s2,s3,s4
The same technique can be used to specify values for s3, s4, and vl. For example:
FILELOAD k,n,m,,,,,vl
Alternatively, specify a zero or negative value for s1 and allow the system to supply the default. The same technique can be used to specify values for s2, s3, and s4. For example:
FILELOAD k,n,m,0,-1,-2,-3,vl
FILELOAD error reporting
If a serious problem arises while the FILELOAD command is running, the user is restarted. A message is issued reporting the completion codes issued by the sorts. The message is:
*** M204.0760: SORT RETURN CODES - SORT 1: xxxxxx, SORT 2: xxxxxx
The completion codes issued by the sorts (xxxxxx) are reported as six hexadecimal digits. The first three digits are the subtask system completion code, such as 0C4. The last three digits are the user completion code, such as 010 (which is a decimal 16). These completion codes can be useful in determining whether a problem is in Model 204 or is in the sort package itself.
FLOD and FILELOAD command output
After the file load program has completed, the following counters are displayed:
| This counter | Displays the number of... |
|---|---|
| RECORDS INPUT | Records read from the TAPEI (input) data set, including those skipped by the FLOD or FILELOAD command |
| ADDS | New Model 204 records begun |
| DELETES | Model 204 records deleted |
| AF | Fields added |
| DF | Fields deleted (not including those deleted through a DELETE command) |
These counters can help you ensure that you have added, deleted, or changed all the records that you intended to.
File Load statements: overview
Model 204 provides several File Load statements that are elements of a separate File Load language.
The file load language provides limited programming capability. If complicated edits or large amounts of data manipulation are required, consider using FLOD exits, a preprocessing program, or a host language or SOUL program to load the file.
All File Load statements follow the FILELOAD command.
See the following sections for details:
- File Load statements: mode bits
- File Load statements: loading a new Model 204 file
- File Load statements: manipulating data areas with string buffers
- File Load statements: working with index registers
- File Load statements: updating existing Model 204 records
- File Load statements: deleting records and fields
File Load statement summary
See Syntax of File Load statements for a complete summary of all statements in the File Load language.
File Load statements: mode bits
Many of the statements described in the next sections use mode bits. These mode bits allow you to specify various options that are discussed here. Most options can be summed.
Note: If numeric sequence numbers are present, you must specify mode bits.
Mode bits summary
| Mode bit | Meaning |
|---|---|
| X'8000' | Begin a new Model 204 record. |
| X'4000' | Delete a field |
| X'2000' | Sort or hash key omitted (specified with X'8000') |
| X'1000' | Delete first occurrence of field |
| X'0800' | Suppress deletion of blanks |
| X'0400' | Translate numeric codes |
| X'0200' | Load all-zero fields as '0' |
| X'0100' | Strip leading zeroes |
| X'0080' | Read and load floating point data |
Begin a new Model 204 record (X'8000')
Mode bit X'8000' causes a new Model 204 record to be started. More than one Model 204 record can begin on each pass through a file load program.
For example, suppose that the input statements for the following example each contained data for two people, with one person's data starting in column 1 and the other's in column 41. The file load program might look like this:
FLOD 5000,5000,0 G SOC.SEC.NO=1,9,X'8000' * begin a new record NAME=10,14 DEPT=24,2 SCALE=26,6 SOC.SEC.NO=41,9,X'8000' * begin a new record NAME=50,14 DEPT=64,2 SCALE=66,6 END
The X'8000' mode bit begins a new record even if the field turns out to be all blank, and is not actually stored in the new record (that is, it is possible to have a Model 204 record that has no fields).
Delete a field (X'4000')
The X'4000' mode bit deletes one field. It is used in conjunction with the read-and-load-a-field statement, as follows:
fieldname=position,length,X'4000'
For more information see File Load statements: deleting records and fields.
Sort or hash key omitted (X'2000')
The X'2000' mode bit allows you to specify that a record in a sort or hash key file does not have a sort or hash key. This mode bit can be used in conjunction with the X'8000' mode bit when reorganizing sort or hash key files. For more information, see Reorganizing sorted and hash key files.
Delete first occurrence of field (X'1000')
The X'1000' mode bit, when combined with the X'4000' and X'0800' mode bits, allows you to delete a specific value from a record. Use the X'4000' mode bit to delete INVISIBLE or VISIBLE fields; the value of the INVISIBLE field must be specified. Use the combined mode bit X'5800' to delete specific values in multiply occurring visible fields. See Deleting a VISIBLE field and Deleting specific values for more information.
Suppress blank deletion (X'0800')
Unless suppressed with mode bit X'0800', the File Load utility automatically deletes leading and trailing blanks from the value string.
Translate numeric codes (X'0400')
Input data sometimes contains information in a coded format. For instance, in the example at the beginning of the section, the department field is expressed as a two-digit code to save space on the input line. The File Load utility can store this code as is. However, if the code is a simple numeric code ranging upwards from 0, you can provide a translation table, using mode bit X'0400', following the read-and-load-a-field statement to convert these codes into full departmental names.
The following sample statement translates and stores a department code:
DEPT=24,2,X'0400' = * Code 0 ACCOUNTING= * Code 1 PERSONNEL= * Code 2 PURCHASING= * Code 3 DATA PROCESSING= * Code 4 = * Code 5 MEN'S CLOTHING= * Code 6 WOMEN'S CLOTHING= * Code 7 NOTIONS= SPORTSWEAR= MILLINERY= ADMINISTRATIVE= .
An input line having '06' in columns 24 and 25 causes the field DEPT=MEN'S CLOTHING to be stored in the new record.
Creating translation tables
To create a translation table:
- Specify mode bit X'0400' on the read-and-load-a-field statement.
- Enter the value strings for codes 0 through n on the next n+1 lines, each starting in column 2 and immediately followed by an equal sign (=). If a particular code is not used, represent it with a line having only an equal sign in column 2 (like codes 00 and 05 in the above example).
- Signal the end of the translation table with a line that contains a period in column 1.
Rules for translation tables
The code in the data area of the input record must be an EBCDIC character representation of a decimal number. A plus sign (+) is permitted; blanks are not.
Translation does not occur and the code itself is stored as the field value in the current Model 204 record under the following circumstances:
- Data area does not contain a correct positive numeric code.
- Code is larger than the translation table.
- Code corresponds to a line for which no value is specified.
Note: Do not confuse numeric codes in the input data with the CODED field type option of Model 204 files. CODED fields affect only the internal storage of the field value and are virtually transparent to the end-user.
Using multiple translation table entries on a single line
Yo u can place more than one translation table entry on a single line using the following rules:
- Value for one entry must immediately follow the equal sign for the preceding entry.
- Last entry on each line must end with an equal sign.
- Entries are numbered just as if each entry appeared on a line by itself.
- Period ending the table must always appear on a line by itself.
The previous example can be written:
DEPT=24,2,X'0400' =ACCOUNTING=PERSONNEL=PURCHASING= DATA PROCESSING==MEN'S CLOTHING= WOMEN'S CLOTHING=NOTIONS=SPORTSWEAR= MILLINERY=ADMINISTRATIVE= .
Loading a constant field using a translation table
At times, you might want to specify a field to add to a Model 204 record rather than taking a value from the input record. To do this, write a read-and-load-a-field statement that specifies a position and length of zero and a translation table that has one entry:
fieldname=0,0,X'0400' value= .
Position zero is a special case that makes no reference to the current input record. For example, if the personnel records for more than one company are kept in the PEOPLE file, the records for each company can be loaded in separate File Load runs.
For a particular run, the following example adds the field COMPANY=Rocket to every record loaded during that run:
COMPANY=0,0,X'0400' Rocket= .
Load zero fields as '0' (X'0200')
Mode bit X'0200' loads all-zero fields as '0'. This option is valid only if used in conjunction with mode bit X'0100' (strip leading zeroes). Use mode bits X'0100' and X'0200' together to strip leading zeroes, but to ensure that a field containing all zeros is stored as '0'. This is useful when a zero field and a missing field have different meanings in the database.
Strip leading zeros (X'0100')
To compress values, you can strip all leading zeroes from certain field values before they are loaded into the Model 204 file using mode bit X'0100'. If a field contains all zeroes, it is stripped completely and is not stored. Unless blank deletion is suppressed, blanks are stripped before zeroes.
Read and load floating-point data (X'0080')
Mode bit X'0080' indicates that the incoming data contains floating- point input. If the field to be loaded is not FLOAT, the field value is converted to a character string for storage. If the field is FLOAT, the value is stored with no conversion.
With the mode bit turned off, character string input to a FLOAT field is converted to a floating-point value, if possible. Exponent format input is converted to numeric form for storage in FLOAT fields, and is left unconverted for non-FLOAT fields.
Floating-point format input to a FLOAT field is stored without conversion, but might be truncated or rounded, depending on its length. For more information about storing values in floating-point fields, see Floating point conversion, rounding, and precision rules.
File Load statements: loading a new Model 204 file
The statements that can be used in a file load program are summarized here. Most file load statements are sensitive to the column in which they begin; note the specifications carefully.
Note: The file load statements use the vertical bar (|) character (that is, the character that has the hexadecimal value X'4F'). If the vertical bar is not available on the terminal being used for the File Load run, use the up-arrow (↑) or caret (^) instead. The broken vertical bar symbol available on some ASCII terminals is not equivalent to the vertical bar. Use the up-arrow or caret for these terminals.
G (go to the next logical record) statement
The G statement consists simply of the letter G in column 1. This statement causes the next logical record of the input data set to be positioned for processing.
Syntax
G
Various other file load statements can then refer to the data in the input record by specifying a relative position within the record. If the input records are of fixed or undefined length (RECFM = F, FB, or U), the data starts in position 1. If the records are of variable length (RECFM = V or VB), the data starts in position 5, and the binary length of the data is in positions 1 and 2.
If no more input records remain, the file load program terminates and Model 204 goes on to the command that follows the END statement.
* statement (comment line)
Comment lines can be inserted anywhere in the file load program. Comment lines must have an asterisk in column 1.
Syntax
* This is a comment
Read-and-load-a-field statement
The read-and-load-a-field statement stores a field (in a Model 204 record) that contains the specified field name and a value extracted from the specified positions of the current input record.
Read-and-load-a-field statement processing
Before the value is stored, leading and trailing blanks are deleted from it for the sake of space saving and uniformity. (In retrieval specifications, Model 204 considers 'MALE' and 'MALE ' to be separate and distinct values.) Internal blanks are not changed in any way; for example: 'A B' is stored as 'A B' and not as 'AB' or 'A B'.
If the specified data area is entirely blank, then deleting the blanks reduces the length of the value to zero and the field is not stored. To load null values, use the LOADNULLS ON statement as described on LOADNULLS statement. Deleting leading and trailing blanks can be suppressed by using mode bits after the length specification.
Syntax
fieldname=position,length,mode_bits
Where:
- fieldname must start in column 2 and must be defined before running the file load program. fieldname must be followed immediately by the equal sign with no intervening blanks.
- position denotes the starting position of the field's value within the input record currently being processed and is always a positive number. (Position zero has a special significance that is explained in Loading a constant field using a translation table.)
- length specifies the number of characters allotted to the value in the input record.
- mode_bits are optional and are described beginning on File Load statements: mode bits.
Load-constant (LDC) statement
The LDC statement loads a constant value into a field. It is more efficient for loading a constant field than the translation table method described in File Load statements: mode bits.
Syntax
LDC fieldname=value=mode_bits
Where:
- LDC begins in column 1.
- fieldname is the Model 204 field into which the constant value is to be loaded.
- mode_bits are optional and are the same as those described beginning on File Load statements: mode bits.
- Equal signs (=) are value delimiters.
Examples
The following examples use the LDC statement:
- Load the value
1176 Binto fieldDEPT NO:LDC DEPT NO=1176 B=
- Load the value
BOSTONinto the fieldCITYand begin a new Model 204 record:LDC CITY=BOSTON=X'8000'
LOADNULLS statement
The LOADNULLS statement allows you to determine how to treat null values. Null values (values with a string length of zero) occur when you delete a data area that is blank.
Syntax
LOADNULLS [ON | OFF]
Where:
- ON means that null values are loaded, the default.
- OFF means that null values are not loaded.
If LOADNULLS is not specified, the initial FLOD state is set to LOADNULLS OFF.
Load-repeating-field (LDRF) statement
The LDRF statement loads a variable number of occurrences of a fixed length field of an input record into a multiply occurring field of a Model 204 record. If the number of occurrences of the fixed length field varies between input records, each input record must contain a field that specifies the number of occurrences. If the number of occurrences of the fixed length field is the same in all input records, the constant value can be loaded into a string buffer, and the LDRF statement can refer to the string buffer. The fixed length fields must be adjacent in the input record.
Syntax
LDRF fieldname=pos1,len1,pos2,len2[,index][,mode_bits]
Where:
- LDRF must begin in column 1.
- pos1 is the starting position within the input record of the first occurrence of the fixed length field.
- len1 is the length of each occurrence of the field.
- pos2 is an EBCDIC number representing the number of occurrences of the fixed length field.
- len2, in bytes, is the length of the number in pos2.
- index is optional and specifies an index register that points, after execution of the statement, to the record position just past the last occurrence loaded.
- mode_bits are optional and described starting on File Load statements: mode bits.
- The pos2 parameter is expected to be in EBCDIC. If this field is in the input record in some form, use the appropriate conversion statement (CFB, CFF, CFP, CFZ), with a string buffer. The string buffer can then be specified in the LDRF statement as the pos2 parameter. See File Load statements: manipulating data areas with string buffers for more information about converting values.
Example
For example, consider a file load program input file for a personnel database. The records might contain skill data that is likely to be multiply occurring. If the skill fields begin at position 45 of the input record, the length of each field is 15 bytes, a two-character EBCDIC occurrence count exists at record position 10, and the data is to be loaded into fields named SKILL, the following statement loads the fields:
LDRF SKILL=45,15,10,2
Label definition (#) statement
Labels can be defined within a file load program by a statement in the form:
#n
Where:
- # (pound sign) is in column 1, and it is the label delimiter.
- n is a positive number. The minimum value for n is 1 (see File load program execution). The maximum is either 4095 or the value of the parameter LNTBL, whichever is smaller.
Usage
Labels are used by these other file load statements:
- Unconditional branch
- Branch-on-character-equal
- CASE statements that transfer execution from one part of the procedure to another.
These related statements are discussed in the following sections.
Unconditional branches
To force the execution of a file load program to transfer unconditionally to a statement other than the next one in line, specify a statement in the following form in column 1:
=label
Where:
label is the "n" portion of the label as described in the previous section.
Branch-on-character-equal (=) statement
The branch-on-character-equal statement allows the execution of a file load program to transfer to a different part of the procedure if the character at a specified position of the input record is equal to a specified character.
Syntax
=label,position,character
Where:
- = (equal sign) is in column 1.
- label is the "n" portion of the label defined elsewhere in the procedure.
- position denotes the position of the character in the input record to be compared.
- character is the EBCDIC character to which the input character is compared. If the characters are equal, execution is transferred to the file load statements following the specified label.
Usage
This statement can compare only one character at a time. The EBCDIC character must immediately follow the second comma in the statement. Be careful about what EBCDIC character you choose; you can only specify an unprintable character if the editor has special input capabilities.
Example
In the following example, certain personnel input records contain the employee's sex (F or M) in column 8, and the employee's spouse's name in columns 20 through 35:
FLOD -1,-1,0 G *Get a record from TAPEI SEX=8,1,X'8000' *Start new rec, load SEX field =10,8,M *Branch to label 10 if SEX is M NAME OF HUSBAND=20,16 *Load husband's name =11 *Branch to 11,skip wife's name #10 *Branch here when SEX is M NAME OF WIFE=20,16 *Load wife's name #11 *Fall through to END statement END
CASE statement
The CASE statement provides a character string compare and branch facility that allows the execution of a file load program to transfer to one of a number of other parts of the procedure based upon the contents of a data field at a specified position of the input record.
Syntax
CASE position,length string1=label1 string2=label2 string3=label3 . . . ENDCASE
Where:
- CASE begins in column 1.
- position denotes the starting position of the character string in the input record to be tested.
- length denotes the length of the character string.
- stringN=labelN specifications form a branch table to indicate where to transfer control when the argument string is matched. Branch table entries must begin in column 2. CASE is limited to 25 or fewer entries.
- ENDCASE, starting in column 1, must be used to terminate the branch table.
Usage
The CASE statement recognizes a match only if the content and length of the input record string argument are identical to the string value and length of one of the branch table entries. If no branch table entry matches the input record string argument, control passes to the statement following ENDCASE.
Example
Consider the following example:
CASE 37,4 JUNE=6 JULY=7 MAY =2 ENDCASE
When the CASE statement is executed, the four-character string that starts at position 37 of the input record is compared to each table entry. A match on content and length results in a branch to the procedure label following the =. Thus, if an input record contained JUNE in positions 37-40, control is transferred to procedure label 6. If the record contained JULY or MAY, control is passed to label 7 or 2, respectively.
The table entry for MAY in the previous example was expanded to four bytes. If the table entry is as follows, a match does not occur because its implies string length is 3:
MAY=2
The comparison is of data content and length. Applications of the CASE statement, in which the length of the strings in the branch table vary, can be handled by using a file load program index register for the CASE length specification. Index registers are discussed in File Load statements: working with index registers.
Transfer-on-condition (T) statement
Use the transfer-on-condition statement to compare two data areas of the input record and to transfer to a specified label if the comparison indicates a specified condition.
Syntax
T label,position1,length,position2,condition
Where:
- T is in column 1.
- label is the "n" portion of the specified label (see previous statements about labels).
- position1 is the position of the first data area.
- length specifies the number of characters.
- position2 is the position of the second data area. Each data area is taken to be and is treated as a simple EBCDIC character string.
- condition is represented by a decimal number, as follows:
Code
Meaning
2
Greater than
4
Less than
7
Not equal to
8
Equal to
11
Greater than or equal to
13
Less than or equal to
Example
The following example transfers to label 40, if the character string in columns 3 through 12 is greater than that in columns 31 through 40:
T 40,3,10,31,2
Read a field name from input data (D) statement
In some circumstances, the input data contains the names of the fields to be loaded as well as the values. The D statement is similar to the read-and-load-a-field statement except that it also specifies the position and length of the field name within the current input.
Syntax
D position1,length1=position2,length2[,mode_bits]
Where:
- D is in column 1.
- position1 and length1 specify the position and length of the data area that contains the field name. Leading and trailing blanks are deleted.
- position2 and length2 specify the position and length of the data area that contains the field value.
- mode_bits are optional and identical to the optional mode bits in File Load statements: mode bits.
Example
Suppose that input statements are arranged so that each statement contains a field name in columns 2 through 31 and a field value in columns 32 through 80. Furthermore, column 1 contains a 1 if the field is the first field of a new record and a 2 otherwise. The input records are:
1SOC.SEC.NO 540237398
2NAME THORNHILL
2DEPT ACCOUNTING
1SOC.SEC.NO 239876433
2NAME DARCY
.
.
.
The following file load program loads the records:
FLOD -1,-1,0
G *Read new input record
=10,1,2 *Branch to 10 if rec starts with 2
D 2,30=32,49,X'8000' *Load first fld of Model 204 rec
=20 *Branch to label 20
#10
D 2,30=32,49 *Add a field to Model 204 record
#20
END
Print a character string (P) statement
Use the P statement to print selected portions of the current input record or of a string buffer.
Syntax
P position,length
Where:
- P is in column 1.
- position indicates the starting position on the input record or string buffer.
- length indicates the number of bytes of data to be printed from the input record or string buffer.
Example
The following statement can be used to print out sample input data:
FLOD -1,50,0
G
P 1,80
END
This statement prints 50 input records of 80 bytes each.
The P statement also is useful for printing out input records that are not in an expected format. The following procedure prints out input records that contain something other than an X or a Y in column 1:
FLOD -1,-1,0
G
=10,1,X * Branch to 10 if first column is X.
=20,1,Y * Branch to 20 if first column is Y.
P 1,80 * Print bad input record.
=30 * Don't process bad record.
#10
.
. * Process X records.
.
=30
#20
.
. * Process Y records.
.
#30
END
STOP statement
The STOP statement allows a file load program to exit before the number of records in the data set or specified in the file load program have been processed.
Syntax
STOP return_code
Where return_code is an optional, nonzero number. This number sets the job step return code for the file load program step.
Usage
When the STOP statement is executed, the file load program ends evaluation of the statements in the procedure and displays the following message:
*** M204.0697: FLOD FINISHED -- STOP STATEMENT
When the file load program STOP statement executes, it ends the program, but not any of the other commands contained in the job stream.
File Load statements: manipulating data areas with string buffers
Two 256-byte areas, called string buffers, are provided to allow you to manipulate and reformat data areas before they are loaded. Use string buffers when:
- Input contains a long data area that is continued over two or more input records
- Number of data areas are to be combined, reordered, or reformatted before loading
- Using a numeric conversion statement (CFB, CFP, CFF, or CFZ)
- Using an L/ENDL loop (see L...ENDL statement (locate existing records))
Use the following statements to manipulate the contents of the string buffers.
Statement
Meaning
S
Clears the string buffer; moves a character string into the buffer
SC
Clears the string buffer; moves a constant into the buffer
M
Appends (moves) a character string into the buffer without clearing
MC
Appends (moves) a constant into the buffer without clearing
CFB
Converts from binary
CFF
Converts from floating-point
CFP
Converts from packed decimal
CFZ
Converts from zoned decimal
Referring to string buffers
Any statement that refers to the normal input record can also refer to a string buffer. A position field in any statement can be modified to refer to the string buffer instead of the input record using the following format:
=position, {|0S | |1S}
Examples
The following example branches to label 12 if column 37 of string buffer 0 contains an A:
=12,37|0S,A
The following example loads a field called DATE with a value taken from the first six columns of string buffer 1:
DATE=1|1S,6
The length of the current contents of a string buffer is remembered by Model 204 and can be used in any statement that contains a length field. This is done by immediately following the length with a vertical bar, the string buffer number, and the letter S. This causes the current length of the specified string buffer to be added to the length field.
Therefore, the length field normally is specified as zero.
The following example loads a field called DATE with a value equal to the current contents of string buffer 1:
DATE=1|1S,0|1S
The following example transfers to label 20, if the current contents of string buffer 0 are less than or equal to (condition 13) the contents of the date area beginning at column 73 of the current record:
T 20,1|0S,0|0S,73,13
For example, certain input records contain Social Security numbers in the form 123-45-6789 in columns 21 through 31. The following code removes the hyphens before the numbers are loaded into the Model 204 file:
S 0,21,3 * Blank buffer; load 3 digits.
M 0,25,2 * Add middle 2 digits.
M 0,28,4 * Add last 4 digits.
SOC.SEC.NO=1|0S,9 * Load number from buffer.
S statement
The S statement clears the contents of the specified string buffer to blanks and then moves in a character string from the current input record. The string is left-justified in the string buffer.
Syntax
The format of the S statement is:
S {0 | 1},position,length
Where:
- S begins in column 1.
- 0 and 1 are string buffers.
- position is the starting column number from which to read characters from the current input record.
- length is the number of characters to read.
Examples
The following example clears buffer 0 and moves 11 characters from columns 29 through 39 of the current input record into the beginning of the buffer:
S 0,29,11
The following example clears string buffer 1 and inserts the character from column 3 of the input:
S 1,3,1
The following example simply clears string buffer 0:
S 0,1,0
M statement
The M statement is almost identical to the S statement except that the string buffer is not cleared first. Characters from the input record are simply appended to the existing contents of the buffer.
Syntax
The format of the M statement is:
M {0 | 1},position,length
SC statement
The SC statement clears the contents of the specified string buffer to blanks and then moves in a constant.
Syntax
The format of the SC statement is:
SC {0 | 1},value=
Where:
- SC begins in column 1.
- 0 and 1 are string buffers.
- value= is any constant string. You must specify the final equal sign. The constant can be up to 256 characters long.
Example
The following example clears buffer 0 and moves the constant value, 7, into the beginning of the buffer:
SC 0,7=
MC statement
The MC statement is almost identical to the SC statement except that the string buffer is not cleared first. A constant value is simply appended to the existing contents of the buffer.
Syntax
The format of the MC statement is:
MC {0 | 1},value=
Data conversion statements
You can use string buffers as an intermediate storage area while converting input data from binary, packed decimal, zoned decimal, or floating-point to EBCDIC for storage in the Model 204 file. Numeric data must be translated to character form if the data is to be accessible to a SOUL user.
These statements are described in detail in the following sections.
CFB (convert from binary) statement
To allow you to translate from binary input data to a character string format for use in Model 204, the convert-from-binary instruction is provided.
Syntax
The statement format is:
CFB {0 | 1},position,length
Where:
- CFB starts in column 1.
- 0 and 1 are string buffers.
- position indicates where the binary data in the input record begins.
- length can be from 1-4 bytes.
Usage
The data in the specified position must be a 1- to 4-byte signed binary number. The CFB instruction converts it to EBCDIC and stores it in the designated string buffer where it can be edited and/or loaded into the Model 204 file. Leading integer zeroes are stripped during conversion.
The first character of the result is either a significant digit or a minus sign (-). If the input value is a zero, the result is a single zero.
Example
For example, the following sequence converts a 2-byte binary field beginning in Position 4 of the input record to EBCDIC, leaving the result in string buffer 1:
CFB 1,4,2
QUANTITY=1|1S,0|1S
The EBCDIC string is loaded from string buffer 1 into the QUANTITY field of the current record.
CFF (convert from floating-point) statement
The convert-from-floating-point instruction converts short- or long-floating-point input data to a character string format for use in Model 204.
Syntax
The statement format is:
CFF {0 | 1},position,length
Where:
- CFF starts in column 1.
- 0 and 1 are string buffers.
- position indicates where the binary data in the input record begins.
- length depends on the form of the input data. The input data can be either a short- or long-precision floating-point number. Length must be:
- 4 for a short-precision number
- 8 for a long-precision number
Note:
If length is specified incorrectly (neither 4 nor 8), a zero length results and no error indication is given.
Usage
Leading integer zeros and trailing fractional zeros are stripped during conversion. A decimal point is not included for an integer value. If the input value is a zero, the result is a single zero. If the input value is a negative number, the first character of the result is a minus sign. The result of the conversion has at least 15 digits of precision. The result of a CFF instruction can be loaded into a Model 204 record using a read-and-load-a-field statement, as shown in the following example.
Example
CFF 1,20,8
AMOUNT=1|1S,0|1S
For information about loading floating-point input directly into a field, see Read and load floating-point data (X'0080').
CFP (convert from packed decimal) statement
To allow you to translate from packed decimal input data to a character string format for use in Model 204, the convert-from-packed instruction is provided.
Syntax
The statement format is:
CFP {0 | 1},position,length[,decimal_position]
Where:
- CFP starts in column 1.
- 0 and 1 are string buffers.
- position indicates where the packed data in the input record begins.
- length, specified in bytes rather than packed decimal digits, must be between 1 and 8.
Note:
If the length is specified incorrectly (less than 1 or greater than 8) a zero length results and no error indication is given.
- decimal_position indicates where a decimal point can be inserted into the string, expressed as a number of digits to the right of the desired decimal point.
Usage
The data in the specified position must be a 1- to 8-byte packed decimal number, which starts on a byte boundary and, therefore, consists of an odd number of digits. This data is not checked for conformity to a packed decimal format. A number is assumed to be positive unless its sign position contains a valid minus sign.
The CFP instruction converts the data to EBCDIC and stores the result in the designated string buffer, where it can be edited and/or loaded into the Model 204 file. The first character of the result is either a blank or a minus sign, and leading and trailing zeros are not stripped. If a decimal position is specified, a decimal point is inserted in the string. If the decimal position is invalid (less than zero or greater than the number of digits in the input), a message is issued and the decimal point is not inserted.
Example
The following sequence converts a 6-byte packed decimal field beginning in Position 8 of the input record to EBCDIC, leaving the result in string buffer 1 with a decimal point inserted, giving the number two decimal places:
CFP 1,8,6,2
AMOUNT=1|1S,0|1S
The result has the form:
sddddddddd.dd
Where:
- s represents a blank or minus sign.
- d represents a digit between 0 and 9.
This result is then loaded into the AMOUNT field of the current record from string buffer 1.
CFZ (convert from zoned decimal) statement
To allow translation from zoned decimal input data to a character string format for use in Model 204, the convert-from-zoned instruction is provided.
Syntax
The statement format is:
CFZ {0 | 1},position,length[,decimal_position]
Where:
- CFZ starts in column 1.
- 0 and 1 are string buffers.
- position indicates where the zoned data in the input record begins.
- length, specified in bytes, must be between 1 and 16. If the length is specified incorrectly (less than 1 or greater than 16), a zero length results and no error indication is given.
- decimal_position indicates where a decimal point can be inserted into the string, expressed as the number of digits to the right of the desired decimal point.
Usage
The data in the specified position must be a 1- to 16-byte zoned decimal number. The data is not checked for conformity to a zoned decimal format. If the zone of the low-order byte is not a valid minus sign, the number is assumed to be positive.
The CFZ instruction converts the data to EBCDIC and stores the result in the designated string buffer where it can be edited and/or loaded into the Model 204 file. The first character of the result is either a blank or a minus sign, and leading and trailing zeroes are not stripped. If the decimal position is invalid (less than 0 or greater than the number of digits in the input), a message is issued and the decimal point is not inserted.
Example
The following sequence converts a 6-byte zoned decimal field beginning in position 20 of the input record to EBCDIC, leaving the result in string buffer 1 with a decimal point inserted, giving the number two decimal places:
CFZ 1,20,6,2
PAYMENT=1|1S,0|1S
The result has the form:
sdddd.dd
Where:
- s represents a blank or minus sign.
- d represents a digit between 0 and 9.
This result is then loaded into the PAYMENT field of the current record from string buffer 1.
File Load statements: working with index registers
A number of work areas called index registers, which are used primarily to manipulate numbers, are available for use within file load programs. The numbers in these index registers are most often used to modify the position or length fields of other file load statements.
Number of allowable registers
Index registers are denoted by index register numbers that can range from 1 to the value of the parameter LNTBL, which defaults to 50 (see File load program execution). The maximum number of index registers is 255, no matter how large LNTBL is.
Index register size
Each index register is four bytes long (a fullword) and can contain number values between -2,147,483,648 and +2,147,483,647, inclusive.
Setting an index register
The I statement has a fairly complicated format. A number of simple forms are discussed first.
Syntax
The basic statement format is:
I index,[operands]
Where:
- I is in column 1.
- index is the number of the index register to be set.
- operands are optional operations that modify the indicated index register and can involve input records or other index registers.
Clearing an index register
If no optional operands are specified, the I statement sets the specified index register to zero. The following example sets index register 15 to zero:
I 15
Setting an index register from the input record
As many as four bytes of data from the current input record can be loaded into an index register, using the following format:
I index,position,length
Where length is the number of bytes of data starting at the specified position that are placed into the specified index register right-aligned and padded with binary zeros on the left if length is less than 4.
Example
The following example loads the first two bytes of the input record into index register 9:
I 9,1,2
If the input records are variable-length (RECFM=V or VB), index register 9 contains the number of characters of data in the record.
Setting an index register to a constant
To set an index register to a specified number:
Syntax
I index,,,number
Where number, which can be specified in decimal, hexadecimal (X'xx'), or character (C'c') form, must be between -32,768 and +32,767, inclusive (two bytes). If a larger value is specified, only the low-order two bytes are used.
Example
The following example sets index register 35 to minus one:
I 35,,,-1
Adding to an index register
A number can be added to the contents of an index register and stored back into that register or some other register.
Syntax
Use the following format:
I index1,,,number|index2
The number must conform to the previous rule for a constant.
Examples
For example, suppose that index register 23 contains the number 119. The following example sets index register 7 to 124. Register 23 still contains 119:
I 7,,,5|23
The following example changes the contents of register 23 from 119 to 99:
I 23,,,-20|23
Multiplying the contents of an index register
The contents of an index register can be multiplied by a specified number and the result stored into that register or some other register.
Syntax
Use the following format:
I index1,,,,number|index2
The number must conform to the rule given above for a constant.
Examples
For example, suppose that index register 4 contains the number 10. The following example sets index register 5 to -10. Register 4 still contains 10:
I 5,,,,-1|4
The following example changes the contents of register 4 from 10 to 70:
I 4,,,,7|4
Full format of I statement
The full format of the I statement is:
I index1,position,length,number2|index2,number3|index3
In this full format the I statement computes the sum of these four quantities:
- Data field of length bytes at the specified position of the current input record
- number2
- Contents of index2
- Product of number3 and the contents of index3
The sum is then stored in index1.
length cannot exceed 4.
number2 and number3 should follow the rule given above for a constant.
Example
The following example adds the two bytes at the beginning of the input record, the contents of index register 15, and the contents of register 16, and stores the result in register 14:
I 14,1,2,0|15,1|16
Modifying position and length fields
The position or length fields of most file load statements can be modified by the contents of any index register by immediately following the field with a vertical bar and the number of the index register. That is:
<span class="squareb"|index
The contents of the index register are added to the position or length number preceding the vertical bar.
Examples
For example, if index register 18 contains 5, the following example branches to label 40 if column 8 of the current input record contains a semicolon (;):
=40,3|18,;
Suppose that an input record contains a data area in columns 20 through 39 that has a person's name in the format:
last_name,first_name
The following code loads a LAST NAME field composed of everything up to the comma:
I 4 *Clear index register 4
#31 *Top of comma loop check
=32,20|4,, *Branch to label 32 if comma found
I 4,,,1|4 *Add one to register 4
=31 *Branch back to label 31
#32
LAST NAME=20,0|4 *Load last name (length in reg 4)
Referring to the contents of index registers
In some cases, an index register can be treated as a data area itself. As such, the index register can be viewed as being four characters long (containing positions 1 through 4).
Any file load statement that has a position field can refer to a position in a specified index register by replacing:
position
with:
indexposition|index*
Where:
- indexposition is 1, 2, 3, or 4 (position 1 is the high-order position).
- index specifies the desired index register. The asterisk replaces the comma that normally follows the position specification.
The following example branches to label 40 if position 4 of index register 11 contains the EBCDIC character 3:
=40,4|11*3
The EBCDIC representation for 3 is equal to the number X'F3', or decimal 243.
Example
The following example branches to label 35 if the contents of positions 1 through 4 of index register 11 are equal to (condition 8) positions 1 through 4 of register 12. In other words, the following instruction simply compares two index registers:
T 35,1|11*4,1|12*8
Printing an index register value
The Q statement prints the current numeric value of a specified index register as a decimal number.
The format is:
Q index
File Load statements: updating existing Model 204 records
You can use file load programs to update or retrieve data from existing records in the Model 204 file as well as to load new records. The FLOD command and JCL are identical to those used for loading new records. The following special purpose file load statements can be used within file load programs to locate existing records, add fields, or determine the current value of an existing field.
L...ENDL statement (locate existing records)
The L statement provides a means of locating all the existing records in the Model 204 file with a specified field name = value pair. The field must be a KEY or ORDERED field. One pass is then made through a locate loop of file load statements for each record located in this way.
Beginning in Model 204 V4R2.0, the L statement supports the ORDERED attribute as well as the KEY attribute. Prior to V4R2.0, you might have defined fields in your files with both the KEY and ORDERED attributes, because you needed the KEY attribute for File Load L statement usage. In such cases, removing the KEY attribute eliminates Table C usage for that field and saves CPU time and disk I/O.
During a particular pass, the located record becomes the current record (that is, the record updated by read-and-load-a-field statements, delete statements, and so on). If a new Model 204 record has begun before the L statement, it is remembered and becomes the current record again when all the located records have been processed by the locate loop. If no records contain the specified field name = value pair, no passes are made through the locate loop.
A locate loop that follows an L statement consists of a sequence of file load statements followed by an ENDL statement. You can use any file load statement except one that transfers control to a label outside the loop (that is, a label that is not between the L and ENDL statements).
Syntax
The format of the L statement is:
L {0 | 1},fieldname=index,label[,mode_bits]
.
.
.
ENDL
Where:
- L is in column 1.
- 0 or 1 specifies the number of a string buffer that contains the value portion of the field name = value pair.
- fieldname must specify a field that has the KEY or ORDERED attribute.
- index specifies the number of any unused index register. The index register is used as a work area by the locate loop.
- label specifies a label to which control is to be transferred after passes have been made through the locate loop for all the located records. If no records are found by the L statement, control passes immediately to the label. For this reason, the statement after the ENDL always needs a label or it is not executed.
- mode_bits are optional and described in File Load statements: mode bits. If default editing produces the wrong value, you must specify mode bits.
- ENDL ends the locate loop and must start in column 1.
Usage
Locate loops can be nested up to three levels. Each time an L statement is encountered, the current record is remembered and record processing is said to go down one level. When the lower locate loop has processed its records, the record processing goes up one level and the remembered record once again becomes the current record. Each nested locate loop operates a FIND against the whole file of records, not just on the found set of the previous loop.
Nesting is shown in the following figure:
Locate Loop Nesting
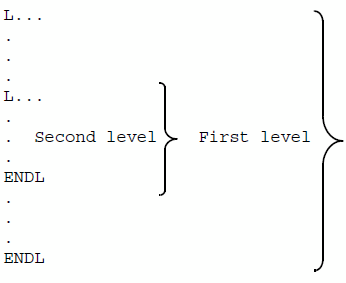
Example
Suppose that a Model 204 file contains personnel information that includes a last name field. The input data contains last names in columns 1 through 20 followed by as many as three homonyms in columns 21-40, 41-60, and 61-80:
FLOD -1,-1,0
G * Get new input record
S 0,1,20 * Move last name into buffer 0
L 0,LAST NAME=30,45 * FR WHERE LAST NAME = last name
HOMONYM=21,20 * Add Homonym Value
HOMONYM=41,20 * Add Homonym Value
HOMONYM=61,20 * Add Homonym Value
ENDL * END FOR
#45
END
For each input record, the previous procedure locates records that contain a LAST NAME equal to the value in columns 1 through 20. For each such record, as many as three HOMONYM fields are added.
A locate loop is quite similar to the following SOUL construction:
LOOP: FOR EACH RECORD WHERE fieldname = value
.
.
.
END FOR
UP and DOWN statements (change record processing level)
The current record processing position can be changed through use of the UP and DOWN statements. The UP and DOWN statements consist of words starting in column 1. They can be used only within locate loops:
- UP statement causes record processing to go up one level. That is, the record that was remembered by the L statement once again becomes the current record and can be updated.
- DOWN statement reverses the process, and the record that the locate loop was processing at the time of the UP statement becomes the current record.
UP and DOWN statements must always occur in pairs.
An L statement performs the DOWN function automatically; an ENDL statement performs an automatic UP.
Example
Suppose that a file contains two types of records: "people" records and "child" records. A number of child records are being loaded into the file. Each contains the name of the child's parent. It is assumed that the parent's record already is in the file. Moreover, the input data for the child records does not include addresses. As each child's record is loaded, this file load program locates the child's parent's record, reads its ADDRESS field, and copies it into the new child record:
FLOD -1,-1,0
G
.
.
.
PARENT.NAME=65,15 *Add PARENT.NAME to child's record
S 1,65,15 *Move parent's name into buffer 1
L 1,NAME=43,20 *FR WHERE NAME = parent's name
F 19,ADDRESS=30,33 * FEO address
UP * Make child's record current
ADDRESS=1|30,0|33 * Add address to child's record
DOWN * Make parent's record current
ENDF * END FOR
#19 * Transfer here at end of F loop.
ENDL *END FOR
#20 *Transfer here at end of L loop.
END
F statement (read field values)
The F statement provides a means of reading the current value(s) of a specified field within the current record. One pass is made through an F loop of file load statements for each occurrence of the field within the record.
Syntax
The format of the F statement is:
F label,fieldname=index1,index2
Where:
- F is in column 1.
- label specifies a label to which control is to be transferred after passes have been made through the F loop for all occurrences of the field.
- fieldname must specify a field that has the VISIBLE attribute.
- index1 and index2 specify numbers of index registers not currently in use.
At the beginning of each pass through the F loop, the value of the field occurrence to be processed in that pass is placed in a special work area, and index1 is pointed at that work area. index2 contains the length of the current value. Thus, the statements within the F loop can refer to the current value by specifying a position of 1|index1 and a length of 0|index2.
After the last pass through the F loop, index1 and index2 still can be used to refer to the last value processed until another F statement is encountered.
An F loop following an F statement consists simply of a sequence of file load statements followed by an ENDF statement. Any file load statement can be used except:
- One that transfers control to a label outside the F loop
- L statement
- Another F statement
- DELETE statement
- Delete-field statement that deletes a VISIBLE field
Example
The following statements delete the last occurrence of the CHILD field in the current record:
F 27,CHILD=35,36
ENDF
#27
CHILD=1|35,0|36,X'4000'
File Load statements: deleting records and fields
Deleting a record
The DELETE statement deletes the current Model 204 record from the file. This statement consists of the word DELETE in column 1.
The following procedure deletes Model 204 records whose Social Security numbers correspond to those read from the input file:
FLOD -1,-1,0
G * Get an input record
S 1,1,9 * Move SSN to string buffer 1
L 1,SOC.SEC.NO=47,15 * FOR EACH matching M204 record
DELETE * Delete the record
ENDL * END FOR
#15
END
The FLOD run must be a multiuser run in order for the NON-DEFFERABLE attribute to take effect at all. How to set up a multiuser run so that the NON-DEFERRABLE attribute takes effect is described in Overriding deferred updates.
Two variations of the read-and-load-a-field statement allow you to delete fields from the current record. One form is limited to deleting VISIBLE fields only. The other form can be used to delete VISIBLE, INVISIBLE, and multiply occurring fields. Descriptions of both variations follow.
Deleting a VISIBLE field
The format of the statement used to delete a VISIBLE field is:
fieldname=1,1,X'5800'
Where:
- fieldname must start in column 2 and must specify a field that has the VISIBLE attribute. If the field occurs in the current record more than once (for example, a
CHILD field), only the first occurrence is deleted.
- 1's are position and length indicators (as in the following subsection).
- X'5800' is a combination of mode bit options (see File Load statements: mode bits).
Example
The following procedure changes the ADDRESS fields of Model 204 records whose Social Security numbers are provided in columns 1 through 9 of the input records. The new addresses are in columns 10 through 59:
FLOD -1,-1,0
G
S 0,1,9 * Move SSN into string buffer 0
L 0,SOC.SEC.NO=15,20 * FR WHERE SOC.SEC.NO=value
ADDRESS=1,1,X'5800' * Delete old address
ADDRESS=10,50 * Add new address
ENDL * END FOR
#20
END
Deleting specific values
Use this form of the read-and-load-a-field statement to delete any field value, even if it is INVISIBLE or a value in a multiply occurring field.
Syntax
The format of the statement used to delete a specific occurrence of a field is:
fieldname=position,length,X'4000'
Where:
- fieldname must start in column 2 and is followed immediately by an equal sign.
- position specifies the starting position within the current input record (or string buffer) of the specific value to be deleted.
- length specifies the length of the value.
- X'4000' is the mode bit option for deleting a field (see File Load statements: mode bits).
This delete-field statement differs from the first delete-field statement in the following ways:
- Value must be specified as well as the field name.
- Form can be used to delete INVISIBLE fields as well as VISIBLE fields.
- It can be used to delete the second, third, and subsequent occurrences of a multiply occurring field, as well as the first occurrence.
Deleting records
The date-time stamp feature does not include support for DELETE RECORD or DELETE RECORDS processing. DELETE RECORD or DELETE RECORDS processing must be handled by your application software.
As well, you can use logical delete techniques. However, in all forms of deleting records, it is your responsibility to maintain a log of record deletions, if you want one.
Handling the date-time stamp field in a file
The DELETE FIELD command is prohibited for the DTSFN field in a file when the FOPT X'10' bit is set. Attempting to do so results in the following message:
M204.2727: CAN'T DELETE DTS FIELD WHEN FOPT=X'10' IS ON
File load program execution
File load program phases
The file load program is processed in two phases. First, all of the statements between the FLOD command and the END statement are compiled. If any errors are detected, such as invalid field names or field-level security violations, the file load program is not executed.
If the compilation is successful, the procedure is executed.
Internal file load optimization feature
Most file load programs add records to a new or partially loaded entry order file (where new records are always added at the end of the file). The internal file load optimization feature greatly optimizes file load program performance in such situations.
The internal file load optimization feature also enhances performance when loading records into new or reinitialized Reuse Record Number (RRN) files.
In other environments, such as sorted, hash key, and unordered files, or for file load programs containing statements that examine or modify data already in the file (DELETE, F, L, or a statement having the X'4000' (delete) mode bit), the internal file load optimization feature is automatically turned off.
Storage tables
File load programs are compiled into various storage and work areas. These areas consist of the following tables:
This table
Contains...
NTBL
Label definitions and index registers. Each NTBL entry is shared by the label and index register having the same number. The size of NTBL determines the highest number that can be used.
QTBL
Statements in internal form. Each file load statement generates one QTBL entry. Entry sizes vary, but most entries are between 12 and 20 bytes long. Important exceptions are the read-and-load-a-field entry, which expands by 4 bytes for each entry in a translation table, and the CASE entry, which starts at 12 bytes and adds 8 bytes for every branch table entry.
STBL
All character strings specified for translation tables, CASE statements, and LDC statements. Each string is preceded by a 1-byte length.
VTBL
Compiler variables. A minimal amount of VTBL space is used if the file load program contains an L statement (locate loop). Entries are variable in length, but most range from 8 to 20 bytes.
The size of each table is determined by a parameter that can be set in the File Load job. These parameters are LNTBL, LQTBL, LSTBL, and LVTBL. For more information about these tables, see Description of tables.
FLOD and FILELOAD exits
FLOD or FILELOAD exits pass control from FLOD to an Assembler or COBOL program, which allows you more sophisticated data manipulation capabilities. For complete information about these exits, see FLOD exits.
Error conditions
This section describes the file load program error conditions that Model 204 can encounter because of preallocated field and field-level security violations.
Errors generated during file load program evaluation are counting errors, which are described in the Rocket Model 204 Terminal User's Guide. If the number of errors encountered during evaluation reaches the limit specified in the ERMX parameter, the file load program is terminated and the user is restarted.
File load performance
The order in which fields are loaded affects the speed with which the file load program executes. This is particularly true when the go-faster feature is in effect. Execution speed can be optimized by loading preallocated fields before all other fields.
Preallocated field violations
If you try to load values in a preallocated field that are longer than the length specified in the field's LENGTH option or you try to add more occurrences to a preallocated field than are specified in the field's OCCURS option, an error is generated during the file load program evaluation. The value lengths specified in file load statements are not checked during compilation. Instead, actual value lengths are checked during evaluation, after blanks have been deleted and leading zeroes have been stripped.
Model 204 handles length and occurrence errors by issuing time error messages that specify the relevant field name and the internal record number of the record that Model 204 was processing when the error was encountered.
Except in the case of the LDRF (load-repeating-field) statement, nothing is stored for the statement that causes the error, and evaluation continues with the next file load statement. For LDRF, the occurrence causing the error is not stored, but Model 204 attempts to load subsequent values.
Field-level security violations
All field-level security (FLS) violations, except those occurring in a D statement used to load field = value pairs from the input data, can be detected during compilation of a file load program. FLS violations detected during compilation result in counting error messages that prevent evaluation of the file load program. An FLS violation that results from the compilation of a D statement produces error messages that identify the input record number, the relevant field name, and the internal record number of the record that was being built when the error was encountered. The field is not stored in the file.
AT-MOST-ONE field violations
When you use FLOD or FILELOAD to load or modify records that have AT-MOST-ONE fields, Model 204 ensures that the new or modified records do not violate AT-MOST-ONE constraints. Model 204 detects and reports all violations of AT-MOST-ONE in one pass of the input data. If Model 204 finds any fields that violate the constraints, the following occurs:
- Error is reported and the new or duplicate field is rejected.
- FLOD continues processing the input data.
- At the end of the run, the file is marked "logically inconsistent."
- Following error message is issued for each violation:
M204.2119: AT-MOST-ONE CONSTRAINT VIOLATION IN RECORD recordnumber, FIELD IGNORED: fieldname=value
NUMERIC VALIDATION file violations
When loading or modifying records in NUMERIC VALIDATION files using FLOD or FILELOAD, Model 204 ensures that the new or modified FLOAT and BINARY fields do not violate NUMERIC VALIDATION constraints. Model 204 detects and reports all FLOAT and BINARY violations. If Model 204 finds any numeric data type violations, the following occurs:
- Error is reported with one of the following messages and the field is rejected.
- FLOD (or FILELOAD) continues processing the input data.
- At the end of the run, the file is marked "logically inconsistent;" that is, the FISTAT parameter is set to X'40'.
- One of the following error messages is issued for each violation:
M204.2123: VALUE SPECIFIED VIOLATES BINARY DATA TYPE VALIDATION IN RECORD recno, FIELD IGNORED:
fieldname = value
M204.2124: VALUE SPECIFIED VIOLATES FLOAT DATA TYPE VALIDATION IN RECORD recno, FIELD IGNORED:
fieldname = value
Syntax of File Load statements
This section provides the complete syntax of the FILELOAD and FLOD commands and all the file load statements.
FILELOAD command
The FILELOAD command has the following format:
Syntax
FILELOAD k,n,m [,[s1] [,[s2] [,[s3] [,[s4] [,vl]]]]]
Where:
- k is the maximum number of records loaded.
- n is the maximum number of passes through the file load procedure.
- m is the number of input records to skip before starting the load process.
- s1 is the amount of memory used for sorting the deferred update index records.
- s2 is the amount of memory used for sorting the deferred update FRV index records.
- s3 is the amount of memory allocated for the two buffers used to pass data from Model 204 to the sorts.
- s4 is the amount of memory allocated for the two buffers used to pass data from the sorts to Model 204.
- vl is the maximum sort record length in variable-length record sorts. (vl corresponds to the L2 of the RECORD sort statement.)
The vl parameter must be present for one-step File Load runs that update ORDERED fields.
FLOD command
Syntax
FLOD k,n,m
Where:
- k, n, and m have the same meanings as in FILELOAD.
Abbreviations
The following abbreviations and terms are used:
Term or abbreviation
Definition
i
Index register number
len
n
n|sS
n|i
Length, specified as one of:
Number
Number + length of current contents of string buffers
Number + contents of index register i
mode
X'8000'
X'4000'
X'2000'
X'1000'
X'0800'
X'0400'
X'0200'
X'0100'
X'0080'
X'8000'
X'4000'
Four-digit hexadecimal number indicating field-loading options:
Begin a new record
Delete the field
Sort or hash key omitted (specified with X'8000')
Delete first occurrence of field
Do not strip leading or trailing blanks
Translation table provided
Load all-zero field as '0'
Strip leading zeroes
Floating-point input
Begin a new record
Delete the field
n,m
Decimal integers
p
n
n|sS
n|i
Position, specified as one of:
Position in current input record
Position in string buffer s
Followed by ,: n + contents of index register i is position in current input record
Followed by *: n is position in index register i
s
String buffer number (0 or 1)
The statements are listed in alphabetical order. Replace elements in lowercase. Uppercase elements appear as shown.
File Load statement
Action
field=p,len,mode
Read-and-load-a-field
CASE p,len
string1=label1
string2=label2
.
.
.
ENDCASE
Branch based on string value
CFB s,p,len
Convert from binary
CFF s,p,len
Convert from floating point
CFP s,p,len,decimal-places
Convert from packed decimal
CFZ s,p,len,decimal-places
Convert from zoned decimal
D p1,len1=p2,len2,mode
Read and load field name and value
DELETE
Delete current record
DOWN
Go down one locate level
END
End of file load program
ENDF
End of F loop
ENDL
End of L (locate) loop
F label,field=i1,i2
Read field value from current record
G
Get new input record
I i1,p,len,n|i2,m|i3
Set i1 to (value of data in position p for len bytes) + n + i2 + (m * i3)
L s,field=i,label
Locate field = string buffer value
LDC field=value=mode
Load constant field
LOADNULLS ON|OFF
Load null values
LDRF field=p1,len1,p2,len2,i,mode
Load repeating field
M s,p,len
Append value to string buffer
MC s,value
Append constant to string buffer
P p,len
Print value
Q i
Print value in index register
S s,p,len
Clear string buffer and load value
SC s,value
Clear string buffer and load constant
STOP
Stop file load program
T label,p1,len,p2,condition
where condition can be:
2 Greater than 4 Less than 7 Not equal to 8 Equal to 11 Greater than or equal to 13 Less than or equal to
Compare strings and branch conditionally
UP
Go up one locate level
XG FLODXTn, c, r, s
Pass fields to FLOD exit program control
#n
Define label n
=label,p,char
Branch to label, optional comparison of char to input
*
Comment
